Hace unos días tenemos disponibles .NET 7 Preview 5. Esta versión incluye mejoras en Generic Math, una nueva API de clasificación de texto para ML.NET con técnicas de aprendizaje profundo para el procesamiento de lenguaje natural, varias mejoras en los generadores de código fuente y un nuevo analizador Roslyn para RegexGenerator y múltiples mejoras de rendimiento en las áreas de CodeGen, Observabilidad, serialización/deserialización JSON y trabajo con flujos.
Observabilidad
Exponer métodos de enumeración de etiquetas ActivityEvent y ActivityLink de alto rendimiento:
var tags = new List<KeyValuePair<string, object?>>()
{
new KeyValuePair<string, object?>("tag1", "value1"),
new KeyValuePair<string, object?>("tag2", "value2"),
};
ActivityLink link = new ActivityLink(default, new ActivityTagsCollection(tags));
foreach (ref readonly KeyValuePair<string, object?> tag in link.EnumerateTagObjects())
{
// Consume the link tags without any extra allocations or value copying.
}
ActivityEvent e = new ActivityEvent("SomeEvent", tags: new ActivityTagsCollection(tags));
foreach (ref readonly KeyValuePair<string, object?> tag in e.EnumerateTagObjects())
{
// Consume the event's tags without any extra allocations or value copying.
}
System.Text.Json
Polymorphism
System.Text.Json ahora admite la serialización y deserialización de jerarquías de tipos polimórficos mediante anotaciones de atributos:
[JsonDerivedType(typeof(Derived))]
public class Base
{
public int X { get; set; }
}
public class Derived : Base
{
public int Y { get; set; }
}
Esta configuración habilita la serialización polimórfica para la clase Base, específicamente cuando el tipo de tiempo de ejecución es Derivado:
Base value = new Derived();
JsonSerializer.Serialize<Base>(value); // { "X" : 0, "Y" : 0 }
Debemos tener en cuenta que no habilita la deserialización polimórfica porque la carga útil sería de ida y vuelta como Base:
Base value = JsonSerializer.Deserialize<Base>(@"{ ""$type"" : ""derived"", ""X"" : 0, ""Y"" : 0 }");
value is Derived; // false
Uso de discriminadores de tipo
Para habilitar la deserialización polimórfica, los usuarios deben especificar un discriminador de tipo para la clase derivada:
[JsonDerivedType(typeof(Derived))]
public class Base
{
public int X { get; set; }
}
public class Derived : Base
{
public int Y { get; set; }
}
Which will now emit JSON along with type discriminator metadata:
Base value = new Derived();
JsonSerializer.Serialize<Base>(value); // { "X" : 0, "Y" : 0 }
que se puede utilizar para deserializar el valor polimórficamente:
Base value = JsonSerializer.Deserialize<Base>(@"{ ""$type"" : ""derived"", ""X"" : 0, ""Y"" : 0 }");
value is Derived; // false
Los identificadores de discriminador de tipo también pueden ser números enteros, por lo que la siguiente forma es válida:
[JsonDerivedType(typeof(Base), typeDiscriminator: "base")]
[JsonDerivedType(typeof(Derived), typeDiscriminator: "derived")]
public class Base
{
public int X { get; set; }
}
public class Derived : Base
{
public int Y { get; set; }
}
Utf8JsonReader.CopyString
Utf8JsonReader.GetString() ha sido la única forma en que los usuarios podían consumir cadenas JSON decodificadas. Siempre asignará una nueva cadena, que podría no ser adecuada para ciertas aplicaciones sensibles al rendimiento. Los métodos CopyString recientemente incluidos permiten copiar las cadenas UTF-8 o UTF-16 sin escape en un búfer propiedad del usuario:
int valueLength = reader.HasReadOnlySequence ? checked((int)ValueSequence.Length) : ValueSpan.Length;
char[] buffer = ArrayPool<char>.Shared.Rent(valueLength);
int charsRead = reader.CopyString(buffer);
ReadOnlySpan<char> source = buffer.Slice(0, charsRead);
ParseUnescapedString(source); // handle the unescaped JSON string
ArrayPool<char>.Shared.Return(buffer);
O si es preferible manejar UTF-8:
ReadOnlySpan<byte> source = stackalloc byte[0];
if (!reader.HasReadOnlySequence && !reader.ValueIsEscaped)
{
source = reader.ValueSpan; // No need to copy to an intermediate buffer if value is span without escape sequences
}
else
{
int valueLength = reader.HasReadOnlySequence ? checked((int)ValueSequence.Length) : ValueSpan.Length;
Span<byte> buffer = valueLength <= 256 ? stackalloc byte[256] : new byte[valueLength];
int bytesRead = reader.CopyString(buffer);
source = buffer.Slice(0, bytesRead);
}
ParseUnescapedBytes(source);
System.IO.Stream
Un error común al usar Stream.Read() es que Read() puede devolver menos datos de los que están disponibles en Stream y menos datos que el búfer que se pasa. Incluso para los programadores que son conscientes de esto, tener que escribir el mismo bucle cada vez que quieren leer de un Stream es molesto.
Para mejorar esta situación, han agregado nuevos métodos a la clase base System.IO.Stream:
namespace System.IO;
public partial class Stream
{
public void ReadExactly(Span<byte> buffer);
public void ReadExactly(byte[] buffer, int offset, int count);
public ValueTask ReadExactlyAsync(Memory<byte> buffer, CancellationToken cancellationToken = default);
public ValueTask ReadExactlyAsync(byte[] buffer, int offset, int count, CancellationToken cancellationToken = default);
public int ReadAtLeast(Span<byte> buffer, int minimumBytes, bool throwOnEndOfStream = true);
public ValueTask<int> ReadAtLeastAsync(Memory<byte> buffer, int minimumBytes, bool throwOnEndOfStream = true, CancellationToken cancellationToken = default);
}
Se garantiza que los nuevos métodos ReadExactly leerán exactamente la cantidad de bytes solicitados. Si Stream finaliza antes de que se hayan leído los bytes solicitados, se lanza una excepción EndOfStreamException.
using FileStream f = File.Open("readme.md");
byte[] buffer = new byte[100];
f.ReadExactly(buffer); // guaranteed to read 100 bytes from the file
Los nuevos métodos ReadAtLeast leerán al menos la cantidad de bytes solicitados. Puede leer más si hay más datos disponibles, hasta el tamaño del búfer. Si la secuencia finaliza antes de que se hayan leído los bytes solicitados, se lanza una excepción EndOfStreamException (en casos avanzados, cuando desea los beneficios de ReadAtLest pero también quiere manejar el escenario de fin de secuencia usted mismo, puede optar por no lanzar la excepción).
using FileStream f = File.Open("readme.md");
byte[] buffer = new byte[100];
int bytesRead = f.ReadAtLeast(buffer, 10);
// 10 <= bytesRead <= 100
Nuevo analizador y reparador Roslyn para RegexGenerator
El nuevo generador de código fuente RegexGenerator, permite generar estáticamente expresiones regulares en tiempo de compilación, lo que resulta en un mejor rendimiento. Primero debemos encontrar lugares en su código donde podría usarse y luego hacer cada cambio de código. Esto suena como el trabajo perfecto para un analizador y reparador Roslyn.
Analyzer
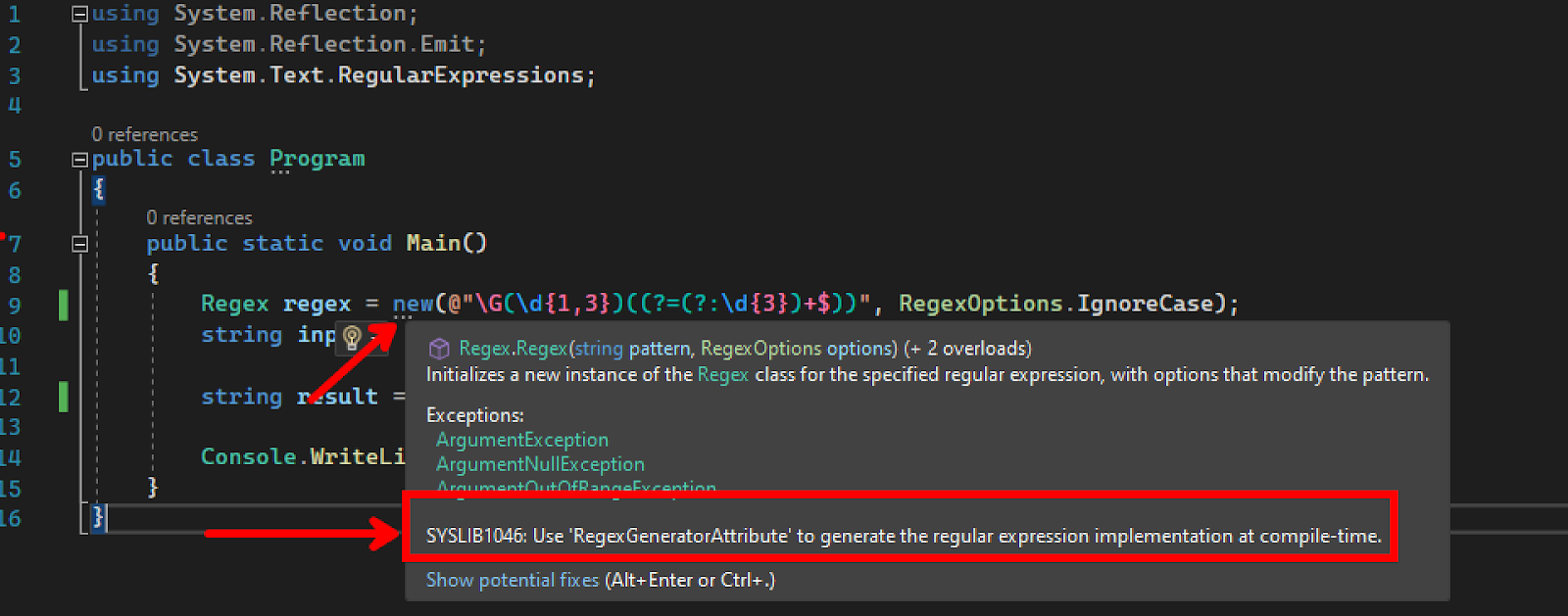
El nuevo analizador buscará usos de Regex que podrían convertirse para usar el generador de fuente RegexGenerator en su lugar. El analizador detectará los usos de los constructores Regex, así como los usos de los métodos estáticos Regex que cumplan con los siguientes criterios:
- Los parámetros proporcionados tienen un valor conocido en tiempo de compilación. La salida del generador fuente depende de estos valores, por lo que deben conocerse en el momento de la compilación.
- Forman parte de una aplicación que tiene como destino .NET 7. El nuevo analizador se envía dentro del paquete de destino de .NET 7 y solo las aplicaciones que tienen como destino .NET 7 son elegibles para este analizador.
- El LangVersion (más información) es superior a 10. Por el momento, el generador de fuentes de expresiones regulares requiere que LangVersion esté configurado en vista previa.
Aquí está el nuevo analizador en acción en Visual Studio:
Code fixer
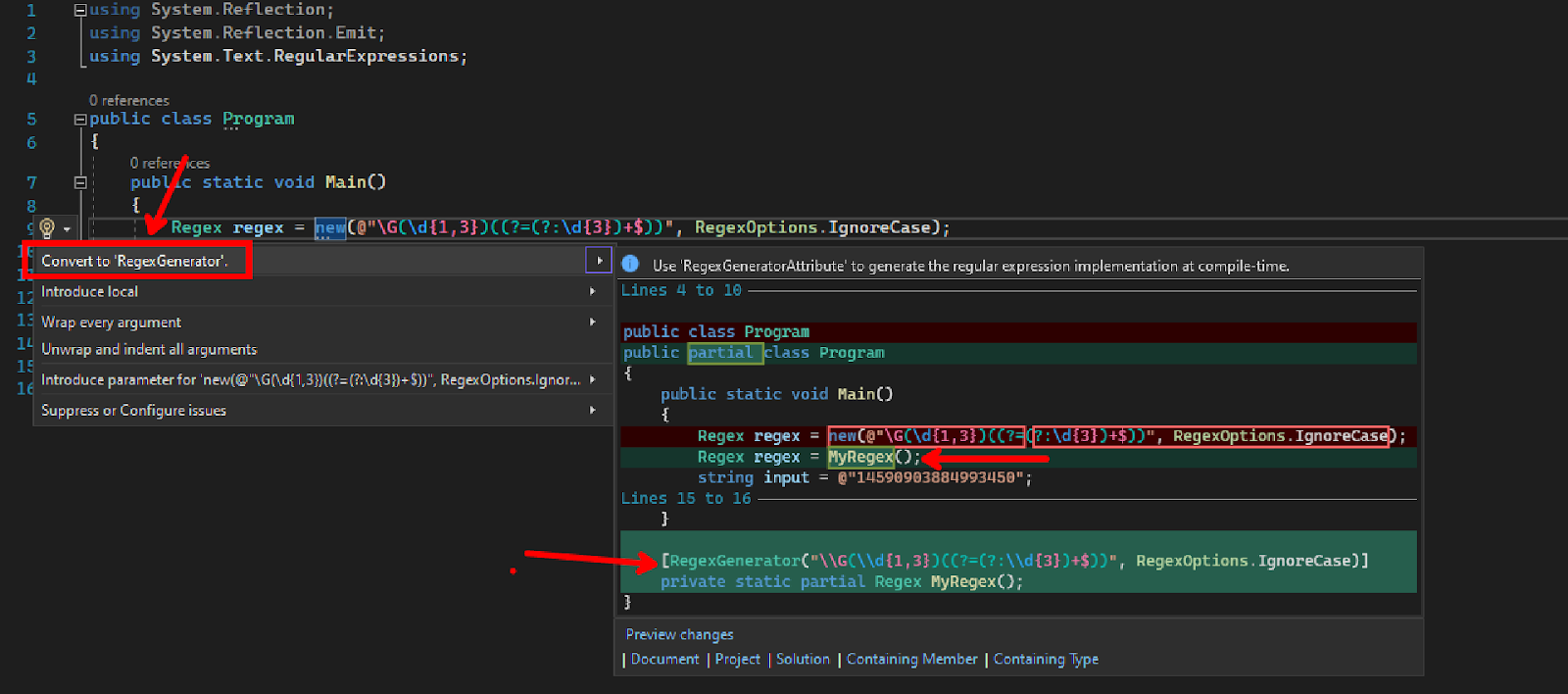
En primer lugar, sugiere un método generador de origen RegexGenerator y le da la opción de anular el nombre predeterminado. A continuación, reemplaza el código original con una llamada al nuevo método.
Aquí está el nuevo fijador de código en acción en Visual Studio:
Generic Math
En la versión anterior, vino una vista previa de una función llamada Matemáticas genéricas que permite a los desarrolladores de .NET aprovechar las API estáticas, incluidos los operadores, desde el código genérico. Esta característica beneficia directamente a los creadores de API que pueden simplificar su base de código. Otros se benefician indirectamente a las API que consumen comenzarán a admitir más tipos sin el requisito de que todos y cada uno de los tipos numéricos obtengan soporte explícito.
En esta versión, se realizaron mejoras en la implementación y se respondieron a los comentarios de la comunidad.
Mejoras en el rendimiento de System.Reflection al invocar miembros
La sobrecarga de usar la reflexión para invocar un miembro (ya sea un método, un constructor o un captador de propiedades) se ha reducido sustancialmente cuando la invocación se realiza varias veces en el mismo miembro. Las ganancias típicas son de 3 a 4 veces más rápidas.
Usando el paquete BenchmarkDotNet:
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Reflection;
namespace ReflectionBenchmarks
{
internal class Program
{
static void Main(string[] args)
{
BenchmarkRunner.Run<InvokeTest>();
}
}
public class InvokeTest
{
private MethodInfo? _method;
private object[] _args = new object[1] { 42 };
[GlobalSetup]
public void Setup()
{
_method = typeof(InvokeTest).GetMethod(nameof(InvokeMe), BindingFlags.Public | BindingFlags.Static)!;
}
[Benchmark]
// *** This went from ~116ns to ~39ns or 3x (66%) faster.***
public void InvokeSimpleMethod() => _method!.Invoke(obj: null, new object[] { 42 });
[Benchmark]
// *** This went from ~106ns to ~26ns or 4x (75%) faster. ***
public void InvokeSimpleMethodWithCachedArgs() => _method!.Invoke(obj: null, _args);
public static int InvokeMe(int i) => i;
}
}
ML.NET Text Classification API
La clasificación de texto es el proceso de aplicar etiquetas o categorías al texto. Los casos de uso comunes incluyen:
- Categorización del correo electrónico como spam o no spam
- Analizar el sentimiento como positivo o negativo de las reseñas de los clientes
- Aplicación de etiquetas a tickets de soporte
La clasificación de texto es un subconjunto de la clasificación, por lo que hoy podría resolver problemas de clasificación de texto con los algoritmos de clasificación existentes en ML.NET. Sin embargo, estos algoritmos no abordan los desafíos comunes con la clasificación de texto ni con las técnicas modernas de aprendizaje profundo.
Ahora con la nueva API de clasificación de texto de ML.NET, nos facilitará el entrenamiento de modelos de clasificación de texto personalizados y trae las últimas técnicas de aprendizaje profundo de última generación para el procesamiento del lenguaje natural a ML.NET.
Conclusiones
Muchas nuevas novedades y muy interesantes para probar e investigar. En próximos posts veremos más novedades sobre .Net 7 hasta la versión final.